Amazon SageMakerを入門向けにいくつかまとめてみました。
(随時 追加していきたいと思います)
- 1. SageMaker サービス全体像
- 2. SageMaker Studio を準備
- 3. Jumpstart で物体検知(YOLO)を試す
- 4. Jumpstart で自然言語処理(BERT)を試す
- 5. SageMaker Autopilot 使用した AutoMLによる機械学習を試す
- 6. データ準備について触ってみる (Data Wrangler)
- 7. SageMaker Pipelines を試す
1. SageMaker サービス全体像
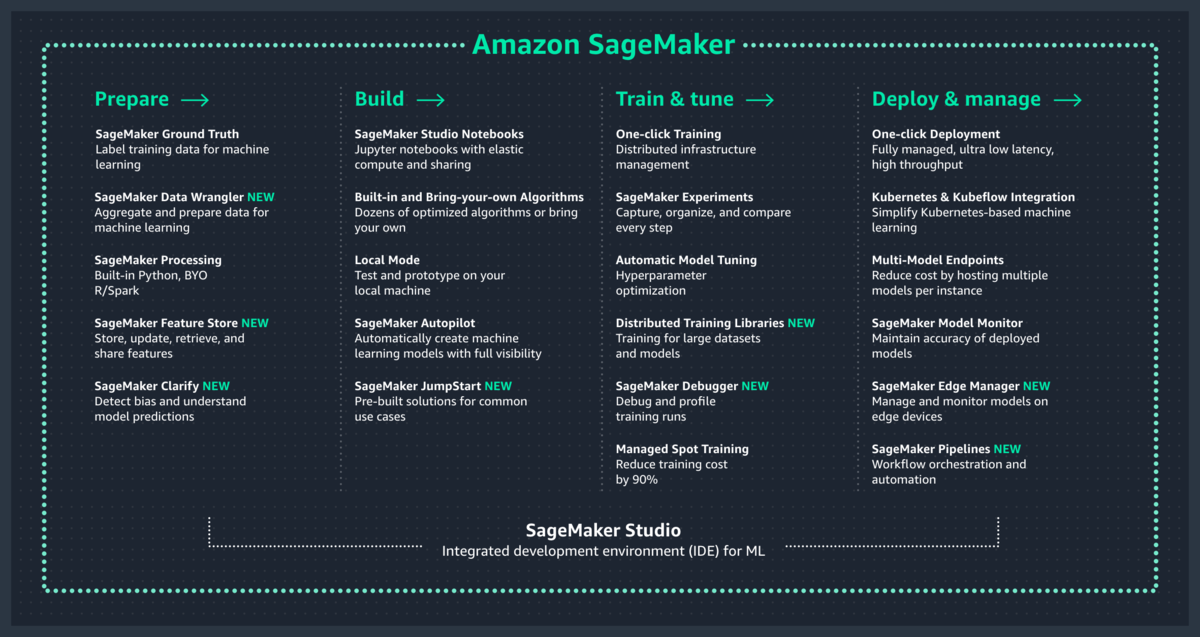
(引用先:https://aws.amazon.com/jp/sagemaker/)
SageMakerには様々な機能が存在しますので、今回は一番入門しやすい部分に絞って触ってみたいと思います。
2. SageMaker Studio を準備
SageMaker を始める際にはまずドメインと呼ばれるを専用環境をVPC内に定義する必要があります。
このドメインの中で学習に必要なインスタンスを立ち上げたり、推論器に使うエンドポイントを使ったりなどをします。
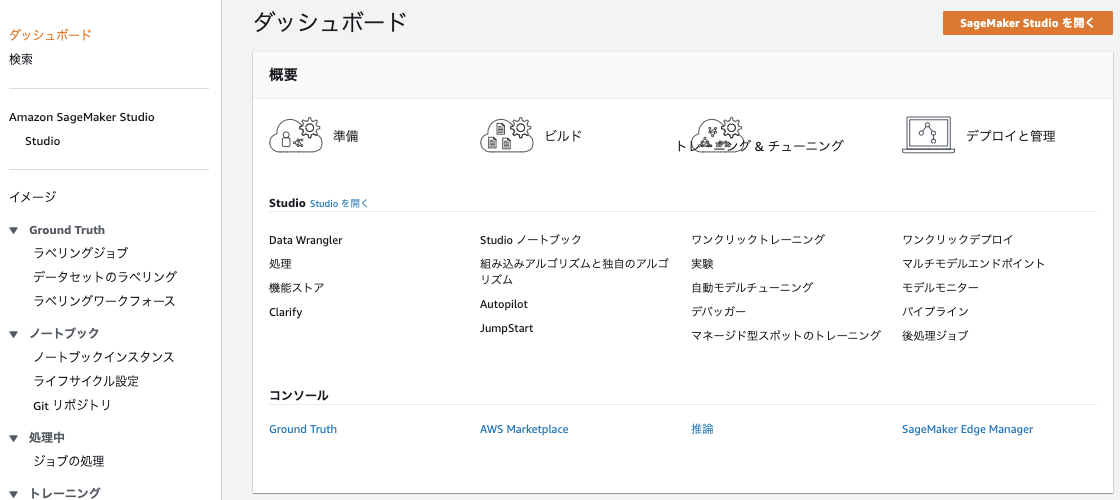
SageMaker用に使う、アクセスロールやVPC、ノートブック共有先、それとJumpStartを設定します(土台の準備)。
JumpStartは事前構築済みモデルなどを使うことができる機能で、機械学習未経験者はまずこれを触っていくのが良いと思います。
しばらくするとDomainのステータスがReadyになります。
この状態ですと関連リソースの定義を行なっているだけで、デプロイしているわけではないため、料金は発生しません。
土台が出来上がったので、利用者を設定していきます。
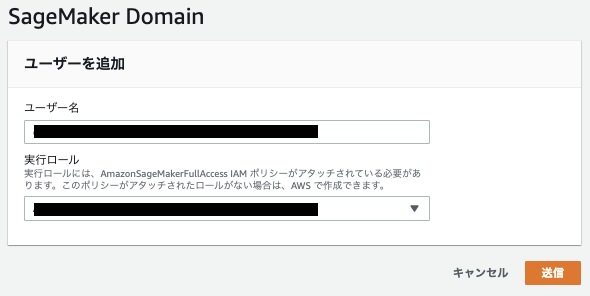
ユーザ作成が完了するとユーザ毎にSageMaker Studioが割り当てられます

3. Jumpstart で物体検知(YOLO)を試す
Studioが立ち上がりましたら、Jumpstartにてモデルを選択します。
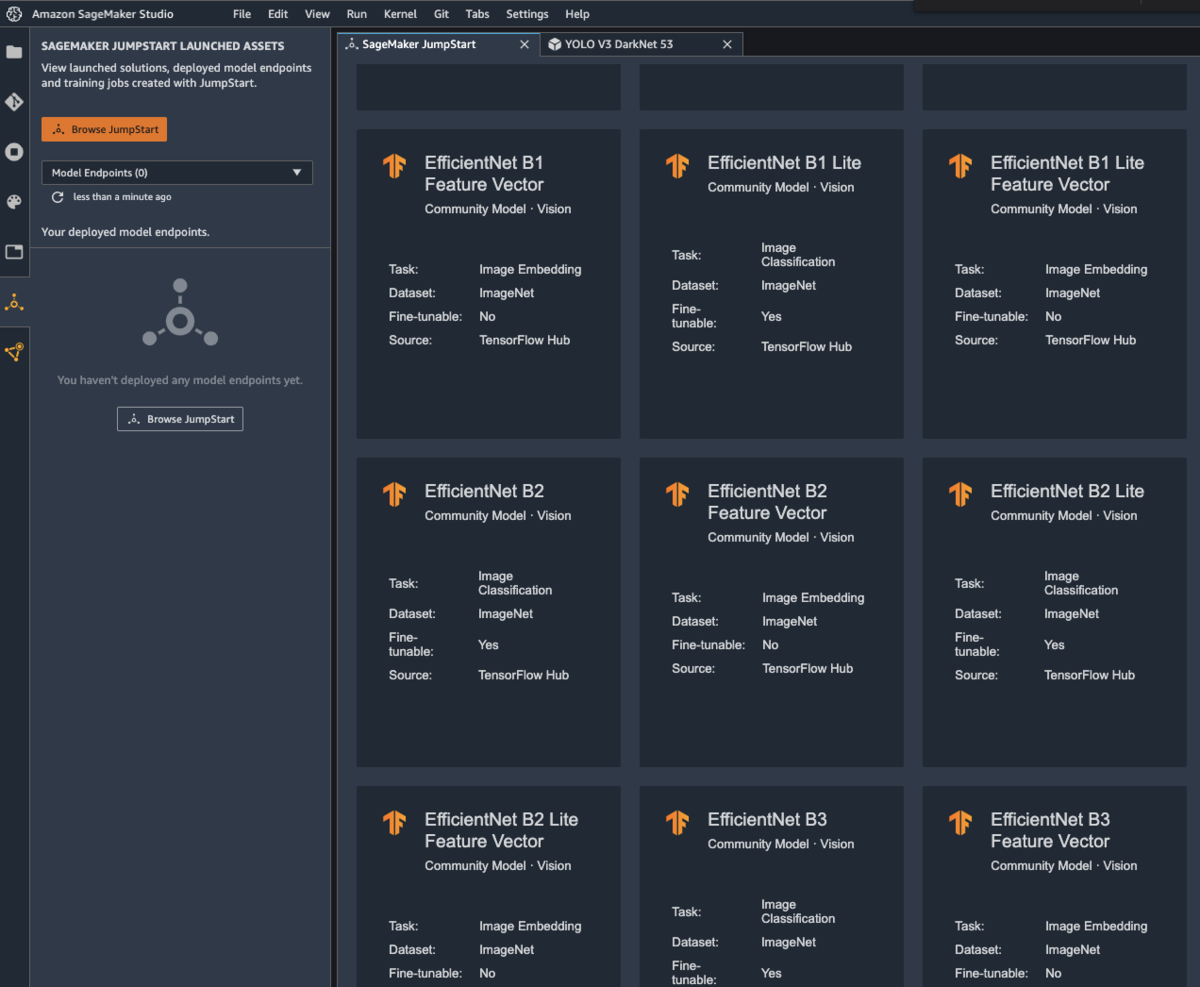
今回は物体検知に使われるYOLOを選択します。
既存のモデルを使うため、このタイミングでEndpointを作成することによって、推論器として利用できます。
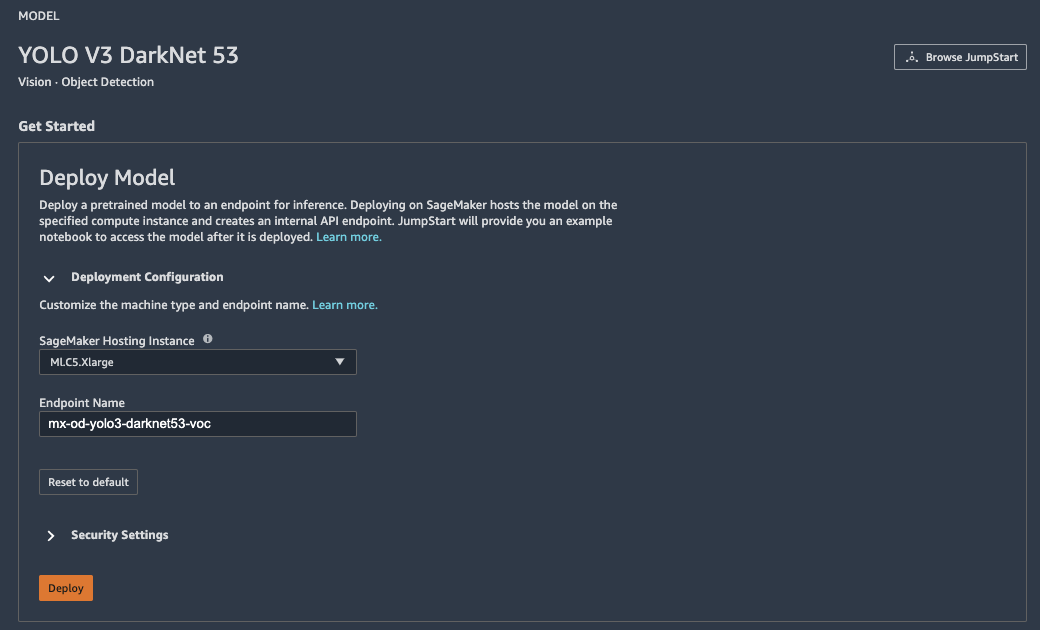
Endpoint Status が「In Service」になりましたら、Notebookを開いて、YOLOモデルを実際に使っていきます。

立ち上げたNotebookのコードを順に実行してトレーニング・モデルの評価を実施します。
今回のモデルセットでは以下の動きをします。
| 順序 | 実行内容 |
|---|---|
| 1 | Jumpstart用のS3からイメージのダウンロード |
| 2 | イメージから物体検知を行い、エンドポイントを作成 |
| 3 | バウンディングボックスにてモデル予測を可視化 |
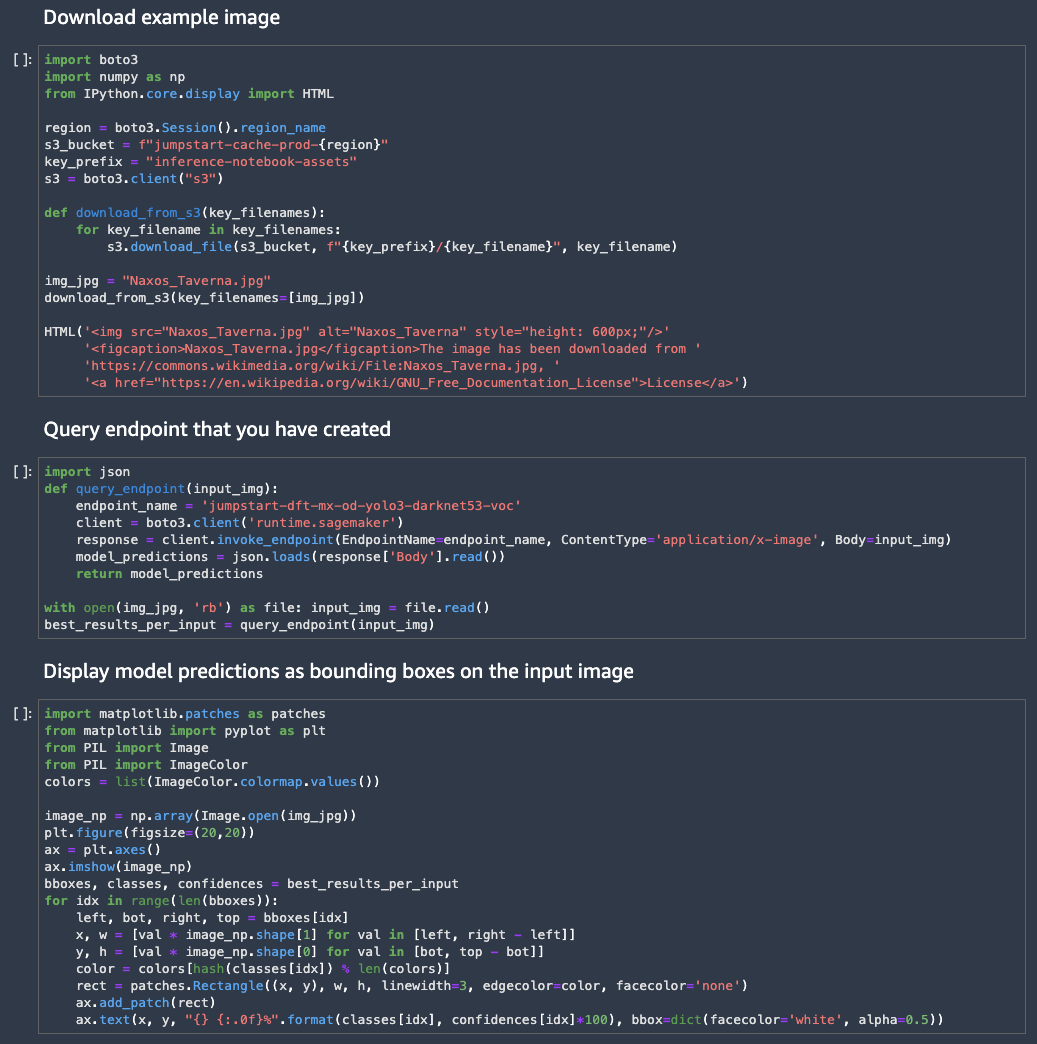
二つ目まで実行すると、下記のように物体検知した座標とそのラベルが決まる
(対象コードにてShift+Enter)
[[[0.3936842679977417, 0.631632387638092, 0.5039596160252889, 0.9389058947563171], [0.15203692515691122, 0.7994152307510376, 0.29037004709243774, 0.9981174468994141], [0.28708767890930176, 0.6139858961105347, 0.3966217041015625, (~snip~) ['chair', 'chair', 'chair', 'chair', 'diningtable', 'chair', (~snip~)
三つ目まで実行すると以下の通り予測結果(バウンディングボックス)が出力される

4. Jumpstart で自然言語処理(BERT)を試す
BERTにて自然言語処理を行います。ここでは、文書内容からポジティブかネガティブかを理解し、出力します。
こちらもYOLOと同様の手順で進めていきます。
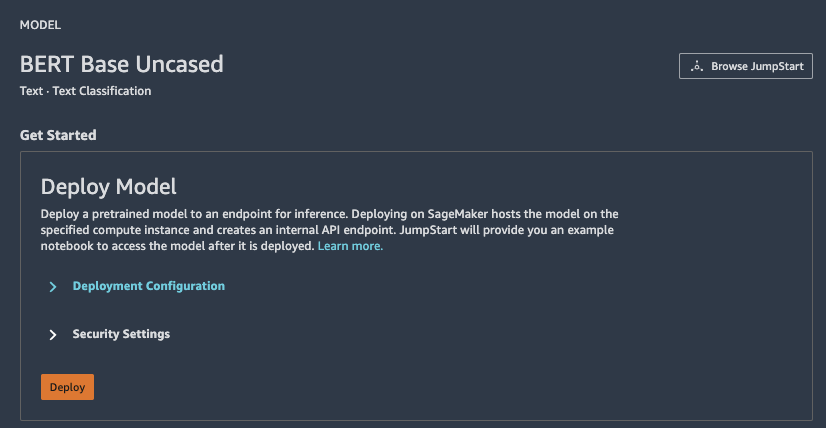
BERTでは以下の動きをします。
| 順序 | 実行内容 |
|---|---|
| 1 | boto3とjsonのインポート |
| 2 | BERTに入力するテキスト2つを定義 |
| 3 | BERTを使ったエンドポイントを作成 |
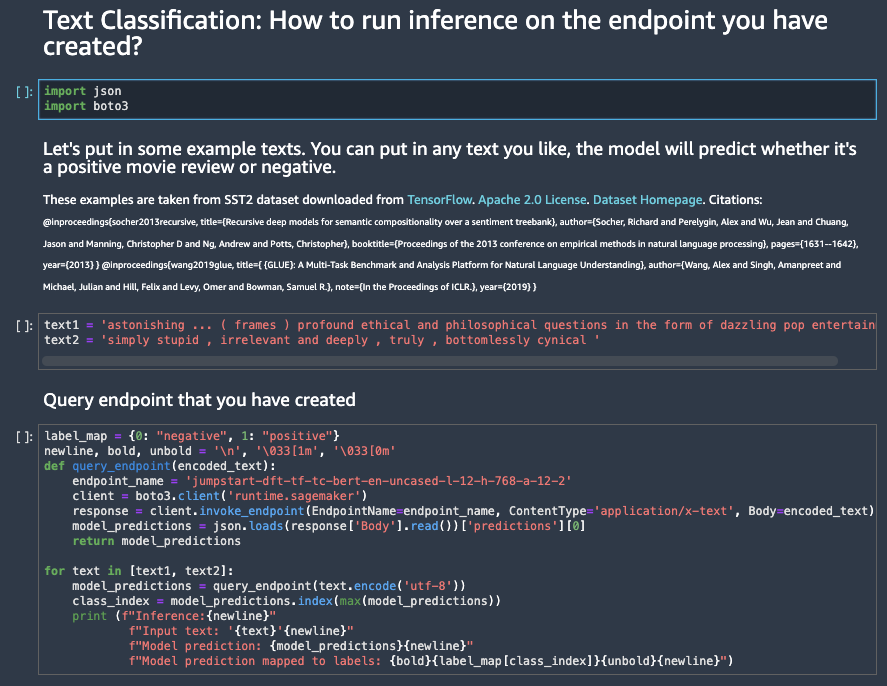
3ステップ実行すると以下の通り2つの予測結果が出力されます。
結果からは上部は「ポジティブ」、下部は「ネガティブ」
Inference: Input text: 'astonishing ... ( frames ) profound ethical and philosophical questions in the form of dazzling pop entertainment' Model prediction: [-4.22542048, 4.55869722] Model prediction mapped to labels: positive Inference: Input text: 'simply stupid , irrelevant and deeply , truly , bottomlessly cynical ' Model prediction: [3.8848784, -4.23237181] Model prediction mapped to labels: negative
Google翻訳した結果は以下ですが、何となくあってるかも。
text1:驚くべき...(フレーム)まばゆいばかりのポップエンターテインメントの形での深い倫理的および哲学的質問 text2:単に愚かで、無関係で、深く、本当に、底なしに冷笑的です
5. SageMaker Autopilot 使用した AutoMLによる機械学習を試す
これまでは既存モデルを使用してデータを作成していましたが、ここではAutoMLを使用した機械学習を進めます。
以下公式サンプルを使用します。このデータセットは銀行の電話でのダイレクトマーケティングを行った結果、口座開設まで至れるかをyes or noで予測するものとなっています。
左のGitタブのから /amazon-sagemaker-examples/autopilot/sagemaker_autopilot_direct_marketing.ipynb をクローンしてきます。
後は上から一つずつ実行していきます。
実行概要は以下になります。
| 順序 | 実行内容 |
|---|---|
| 1 | sagemakerやboto3といった必要なライブラリをインポート |
| 2 | 機械学習に使うデータセットのダウンロード |
| 3 | S3にデータセットをアップロード |
| 4 | SageMaker Autopilot ジョブを設定 |
| 5 | SageMaker Autopilot ジョブを実行 |
| 6 | SageMaker Autopilot ジョブの進捗をトラッキング |
| 7 | 結果 |
6.の進捗で AnalyzingData -> FeatureEngineering -> ModelTuning -> GeneratingExplainabilityReport -> Completed と変化しており、
特徴量エンジニアリングやハイパーパラメータチューニングなどを自動で行なっています。
この時のジョブに関しては以下コンソールの「処理中」から確認できます。

今回の学習結果で以下の通り口座開設に至った結果を出力しています。
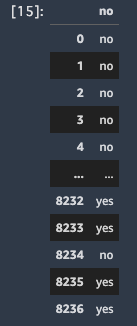
出力全体を確認したい場合はS3の inference_result.csv に出力されるのでそこを確認します。
6. データ準備について触ってみる (Data Wrangler)
機械学習用のデータ収集、前処理を行う場合は Data Wrangler を使います。
今回は以下鉄板不良のデータセット(CSV)を使用します。
データセットをにS3コンソールからアップロードします。

S3から Data Wrangler にインポート。

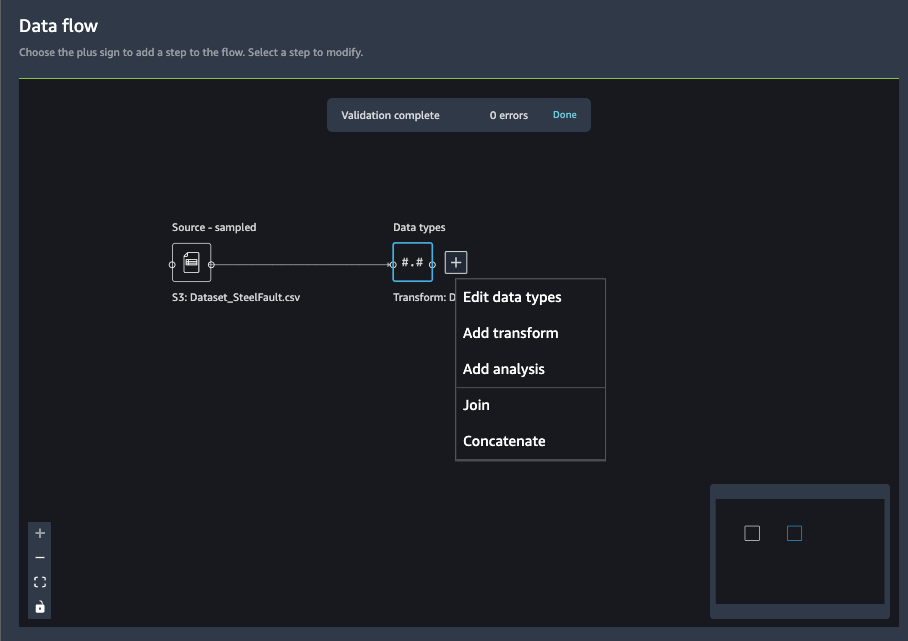
Data flow として表示され、データを変換したり分析したりといったことが可能になります。
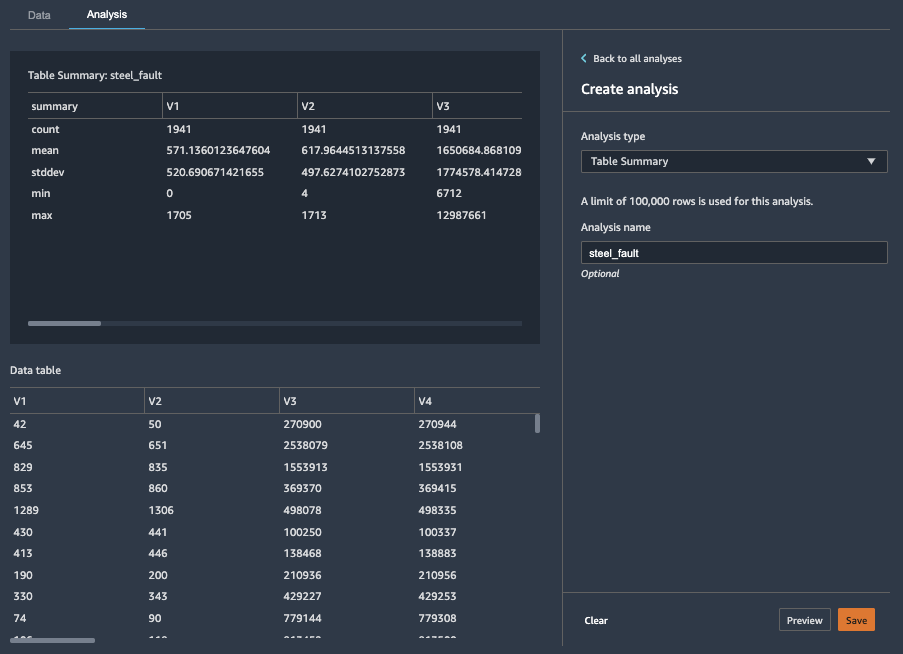
データ分析する場合は以下の通りテーブルやグラフなど様々形で可視化できます。
データ変換の場合は以下の通りデータフローをUIから設定できる
7. SageMaker Pipelines を試す
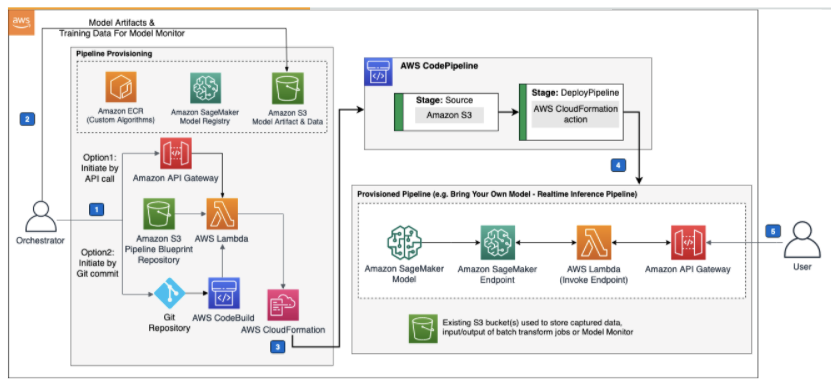
(https://aws.amazon.com/jp/solutions/implementations/aws-mlops-framework/?nc1=h_ls)
主に以下を使っていきます。
サービスカタログにはJumpStartを有効化ことでMLOps用のテンプレートが使えるようになります。
今回は以下を使用します。
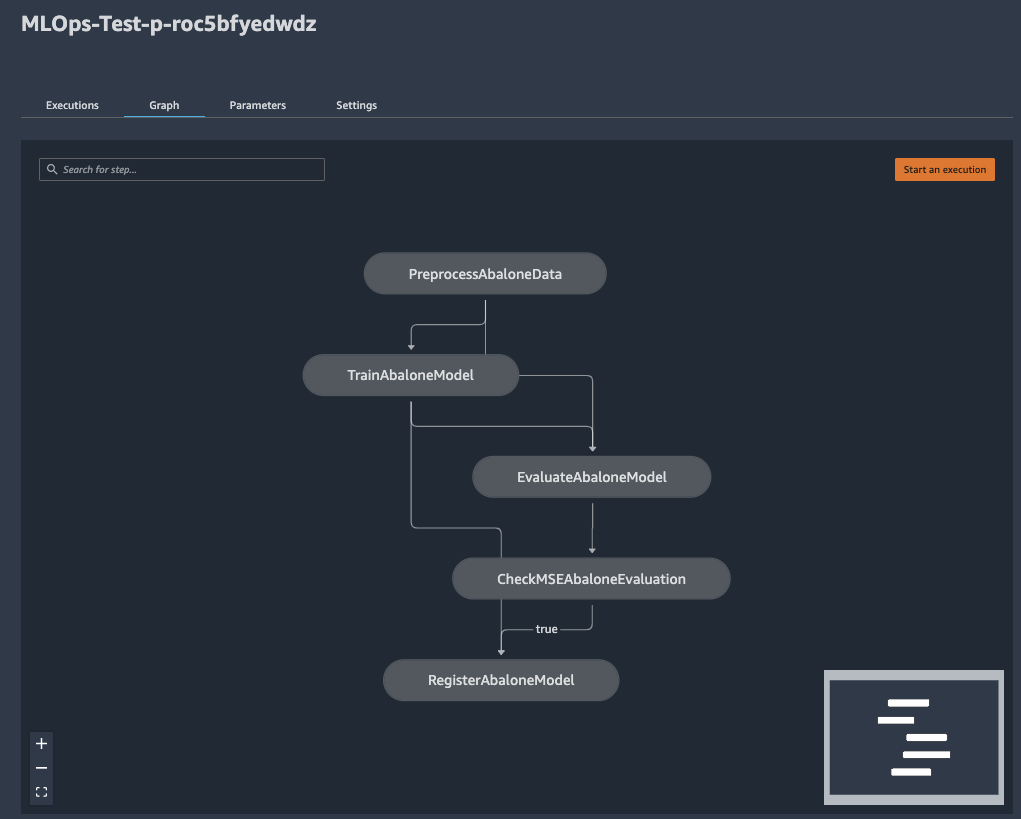
プロジェクトを開始することによりCloudFormationによるMLOpsに必要な環境が作成されます。 以下はMLパイプライン
CodeCommitにはMLOpsに必要なレポジトリが格納されます。
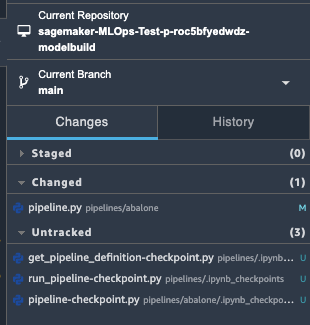
pipelines/abalone/pipeline.py の transform_instances を適当に編集します。
ml.m5.large -> ml.m5.xlarge
そうすると以下の通り Changedが1になります。この状態でpushを行い、パイプラインを回していきます。
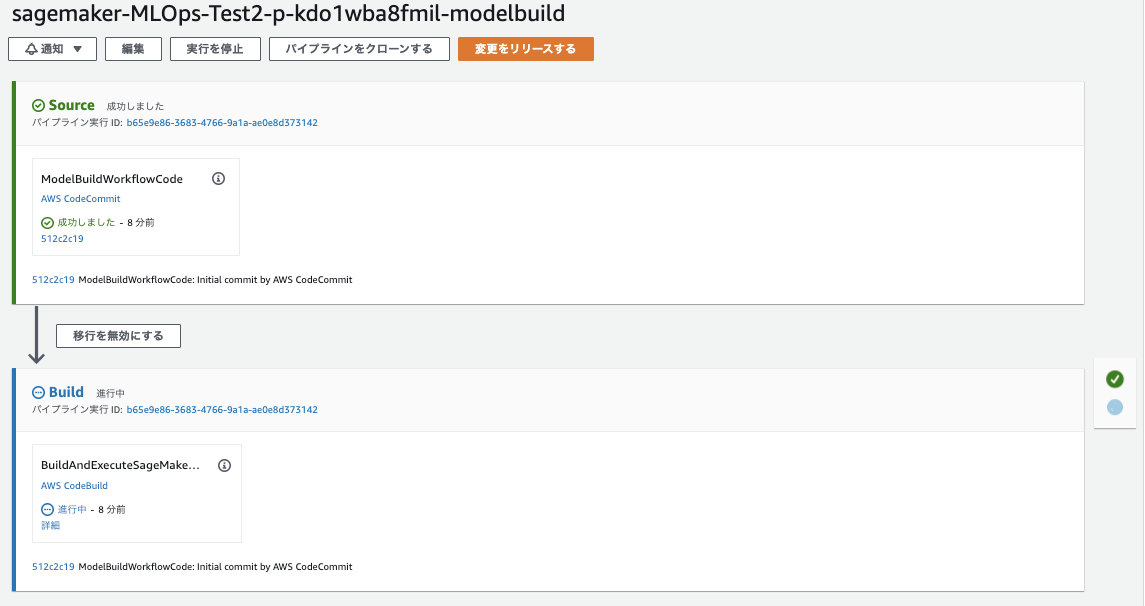
pushすると下記の通り Codebuild が実行されます。

SageMaker Pipeline もCodePipelineで実行されていることが確認できます。
入門編として概要レベルで実践してみました。
次回は詳細にMLOps構築を進めていきます。
以上