先日ドミノピザでLサイズのピザとウルトラジャンボサイズのピザを注文したら、ウルトラジャンボサイズの大きさがすごかった。

左がLサイズで右がウルトラジャンボサイズ
噂通りやばかったので、覚悟して注文した方が良さそう。
先日ドミノピザでLサイズのピザとウルトラジャンボサイズのピザを注文したら、ウルトラジャンボサイズの大きさがすごかった。
左がLサイズで右がウルトラジャンボサイズ
噂通りやばかったので、覚悟して注文した方が良さそう。


どうでしょう?
コツ
Terraform にてAWS、GCP、Azure を使ったマルチクラウドを構築してみました。
今回使うgithubレポジトリは以下になります。
https://github.com/vn-cdr/multicloud-docker
Terraform にて自由な形式のマルチクラウド環境を短時間で用意し、様々なケースを想定したアプリケーション開発役立てたい。
以下クラウドをVPNで繋げてDirectory Serviceを設定するところまでを対象にしたいと思います。
Docker コンテナ上であれば、プラットフォームを気にすることなくTerraformが使えます。
AWS/Azure/GCP APIクライアントを一つのコンテナにて管理するようにする。複数にしても管理が大変なだけ。
※terraformコマンドをローカルホスト上で実行できるようにしたいが、今後別途考える

Terraform実行のためにAPIクライアントを準備します。 各クラウドでAPI用ユーザの作成方法がやや異なります。
AWSでは一般ユーザと同じIAM画面で作成できます。
認証に必要なパラメータ
AWS_ACCESS_KEY_ID="<aws_access_key_id>" AWS_SECRET_ACCESS_KEY="<aws_secret_access_key>"
取得手順:
① IAMにてユーザを作成する

② ユーザ設定

③ ユーザの権限設定

④ タグ設定(オプション)

GCPでは サービスアカウント にてCLIアクセスが可能になります。 サービスアカウントでは扱うアカウント情報が多いためか一般的にjsonファイルを指定してCLIアクセスするようです。
<account名>.json
※今回account名はgcp-service-accountで設定します。
取得手順: サービスアカウント作成
① サービスアカウントの作成

② サービスアカウントのアカウント情報を取得

③ サービスアカウント権限の有効化
Azureでは サービスプリンシパル というユーザにてCLIアクセスを可能にします。
export ARM_SUBSCRIPTION_ID="<arm_subscription_id>" export ARM_CLIENT_ID="<arm_client_id>" export ARM_CLIENT_SECRET="<arm_client_secret>" export ARM_TENANT_ID="<arm_tenant_id>"
① アプリの登録

② 新規ユーザ作成

③ 必要事項入力

今回Terraform で構築するマルチクラウド論理構成は以下のようになります。

cd multicloud-docker mkdir ./.secret cat << EOL > ./.secret/admin-rc.txt # AWS Credential AWS_ACCESS_KEY_ID="<aws_access_key_id>" AWS_SECRET_ACCESS_KEY="<aws_secret_access_key>" # Azure Credential export ARM_SUBSCRIPTION_ID="<arm_subscription_id>" export ARM_CLIENT_ID="<arm_client_id>" export ARM_CLIENT_SECRET="<arm_client_secret>" export ARM_TENANT_ID="<arm_tenant_id>" EOL # GCPサービスアカウントファイルは以下に配置 vi ./.secret/gcp-service-account.json
# サンプルからコピー cp terraform.tfvars.sample terraform.tfvars # e.g. を参考に変数を埋める (詳しくは 5.3. terraform.tfvars を参照ください) vi terraform.tfvars
# コンテナビルド docker build . -t multicloud-docker:latest # コンテナ起動 docker run -it --name multicloud-docker --env-file .secret/admin-rc.txt multicloud-docker:latest # コンテナに入れたことを確認 root@9f2f313b91bc:~# ls aws azure google main.tf providers.tf terraform.tfvars variables.tf vpn
# Terraform 初期設定 terraform init # tfファイルのフォーマットチェック terraform fmt -check # Terraform 実行計画 terraform plan # Terraform 実行 time TF_LOG=debug TF_LOG_PATH="./terraform_log_`date "+%Y%m%d-%H%M%S"`" terraform apply
GCPのAPIが無効になってエラーになる場合は有効化しておいてください。
terrafrom上でも有効化、無効化は可能ですが、エラーなどで意図せず有効化さたままになってしまうことを防ぐため、今回terraformには含めませんでした。
以下のようなエラーになる場合は terraform applyを再実行してくさい.
Error: Error creating customer gateway: MissingParameter: The request must contain the parameter ipAddress
status code: 400, request id: XXXXXXXXX
on vpn/aws.tf line 49, in resource "aws_customer_gateway" "azure":
49: resource "aws_customer_gateway" "azure" {
# エラーなく以下の通りメッセージが出ればデプロイ完了です Apply complete! Resources: 65 added, 0 changed, 0 destroyed. real 59m21.090s user 0m12.054s sys 0m22.781s root@99ae86e95c98:~#
最後に動作確認の手順を記載します。 AWS、GCP、Azureで同じ準備が必要になります。
①AWS、GCP、Azure、にて以下条件でインスタンスを立ち上げる
②ファイアウォールまたはACLの穴あけが必要ですので、各クラウドのVPCに紐づいているACLに穴を開けてください
③外部IP(GIP)を設定している場合はsshできることを確認してください
下記の通りprivate-ipにtracepathすると インターネットを経由せずにAWS-GCP間で疎通が通ることを確認できる。 これはVPNトンネルにて通信がフォワーディングされているためである。
vn-cdr@instance-1:~$ tracepath 10.0.21.84
1?: [LOCALHOST] pmtu 1390
1: no reply
2: 10.0.21.84 30.783ms reached
Resume: pmtu 1390 hops 2 back 2
vn-cdr@instance-1:~$
※インターネットを通ってしまう場合や疎通できない場合はVPC周りのルートまたはファイアウォールを確認すること
処理を担うtfファイルは、なるべくサービスごとに分けて作成
.
├── aws
│ ├── dns
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ └── vpc
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
├── azure
│ └── vnet
│ ├── main.tf
│ ├── output.tf
│ └── variables.tf
├── google
│ └── vpc
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
├── main.tf
├── providers.tf
├── terraform.tfstate
├── terraform.tfstate.backup
├── terraform.tfvars
├── terraform.tfvars.sample
├── variables.tf
└── vpn
├── aws.tf
├── azure.tf
├── google.tf
└── variables.tf
変数群は./providors.tf ./terraform.tfvars を順次読み込み
↓
AWSのawsのvpc、dns作成(./main.tf)
↓
GCPのVPC作成(./google/vpc/main.tf)
↓
AzureのVNET作成(./azure/vnet/main.tf)
↓
VPNに必要なVGW作成をAWS GCP Azure順で作成(./vpn/{aws.tf, google.tf, azure.tf})
↓
設定に問題がなければここで各クラウドの VGW でステータスが BGP Established になる
Dockerfileでは各クラウドでterraformを実行するために必要なパッケージをインストールするように設定している。
FROM python:3.8 ARG pip_installer="https://bootstrap.pypa.io/get-pip.py" ARG awscli_version="1.16.168" # install aws-cli RUN pip install awscli==${awscli_version} # install sam RUN pip install --user --upgrade aws-sam-cli ENV PATH $PATH:/root/.local/bin # install command & azure-cli. RUN apt update && apt install -y less vim wget unzip curl npm && npm install azure-cli # install terraform. RUN wget https://releases.hashicorp.com/terraform/0.14.4/terraform_0.14.4_linux_amd64.zip && \ unzip ./terraform_0.14.4_linux_amd64.zip -d /usr/local/bin/ # copy resources. COPY ./main.tf /root/ COPY ./providers.tf /root/ COPY ./variables.tf /root/ COPY ./aws /root/aws COPY ./google /root/google COPY ./azure /root/azure COPY ./vpn /root/vpn COPY ./.secret/gcp-service-account.json /root/.config/gcloud/gcp-service-account.json COPY ./terraform.tfvars /root/ # initialize command. ENTRYPOINT ["/bin/bash"] WORKDIR /root
以下の通りTerraform実行に必要な引数を定義している。構築リージョンや各PWなどをここで設定します。
aws_dns_suffix = "" # e.g. "compute.internal" aws_directory_service_password = "" # e.g. "Password123!" google_region = "" # e.g. "us-central1" google_project_id = "" # e.g. "sample-project" google_service_account_json = "" # e.g. "gcp-service-account.json" azure_resource_group_name = "" # e.g. "resource_group" azure_location = "" # e.g. "westeurope"
| 項目 | 説明 |
|---|---|
| aws_dns_suffix | AWS Managed Microsoft AD に使うDNSサフィックスを設定してください |
| aws_directory_service_password | AWS Managed Microsoft AD に使うパスワードを設定してください |
| google_region | リソースを作成するGCPのリージョンを設定してください |
| google_project_id | 使用する Project ID を設定してください |
| google_service_account_json | 使用するサービスアカウントのjsonファイルを指定してください |
| azure_resource_group_name | Azureで作成するリソースグループを設定してください |
AWS全体に必要な変数はここに書きます。VPC、DNS、VPNはモジュール化します。
./main.tf
module "aws_vpc" {
source = "./aws/vpc"
vpc_name = "aws-test"
cidr_block = "10.0.0.0/16"
subnet_count = 1
}
module "dns" {
source = "./aws/dns"
vpc_id = module.aws_vpc.vpc_id
directory_name = "test.internal"
directory_password = var.aws_directory_service_password
dns_subnet_cidr_prefix = "10.0.0.0/20"
private_route_table_id = module.aws_vpc.private_route_table_id
}
module "vpn" {
source = "./vpn"
aws_vpc_id = module.aws_vpc.vpc_id
aws_route_table_ids = [module.aws_vpc.private_route_table_id, module.aws_vpc.public_route_table_id]
dns_network_acl_id = module.dns.dns_network_acl_id
}
./providers.tf
terraform {
required_providers {
aws = "~> 2.39.0"
}
}
provider "aws" {
region = var.aws_region
}
./variables.tf
variable "aws_region" {
type = string
description = "aws region to use"
}
variable "aws_dns_suffix" {
type = string
description = "DNS suffix Setting"
}
variable "aws_directory_service_password" {
type = string
description = "password to use for the aws directory service (enabling DNS)"
}
VPC周りはここに書きます。VPC、subnet、セキュリティグループ、ルーティングテーブルなどを作成します。
resource "aws_vpc" "main" {
cidr_block = var.cidr_block
tags = {
Name = var.vpc_name
}
}
resource "aws_subnet" "private" {
count = var.subnet_count
vpc_id = aws_vpc.main.id
cidr_block = cidrsubnet(var.cidr_block, 4, count.index * 2 + 1)
tags = {
Name = "private-subnet-${count.index}"
}
}
resource "aws_subnet" "public" {
count = var.subnet_count
vpc_id = aws_vpc.main.id
cidr_block = cidrsubnet(var.cidr_block, 4, count.index * 2 + 2)
tags = {
Name = "public-subnet-${count.index}"
}
}
resource "aws_network_acl" "public" {
vpc_id = aws_vpc.main.id
subnet_ids = aws_subnet.public[*].id
ingress {
protocol = "tcp"
rule_no = 100
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 80
to_port = 80
}
ingress {
protocol = "tcp"
rule_no = 200
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 443
to_port = 443
}
ingress {
protocol = "tcp"
rule_no = 400
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 1024
to_port = 65535
}
ingress {
protocol = "udp"
rule_no = 500
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 1024
to_port = 65535
}
ingress {
protocol = -1
rule_no = 1000
action = "allow"
cidr_block = aws_vpc.main.cidr_block
from_port = 0
to_port = 0
}
egress {
protocol = -1
rule_no = 100
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 0
to_port = 0
}
tags = {
Name = "public-acl"
}
}
resource "aws_network_acl" "private" {
vpc_id = aws_vpc.main.id
subnet_ids = aws_subnet.private[*].id
ingress {
protocol = "tcp"
rule_no = 400
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 1024
to_port = 65535
}
ingress {
protocol = "udp"
rule_no = 500
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 1024
to_port = 65535
}
ingress {
protocol = -1
rule_no = 1000
action = "allow"
cidr_block = aws_vpc.main.cidr_block
from_port = 0
to_port = 0
}
egress {
protocol = -1
rule_no = 100
action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 0
to_port = 0
}
tags = {
Name = "private-acl"
}
}
# Gateways
resource "aws_internet_gateway" "gw" {
vpc_id = aws_vpc.main.id
tags = {
Name = "${var.vpc_name}-internet-gateway"
}
}
resource "aws_eip" "nat" {
vpc = true
tags = {
Name = "nat-elastic-ip"
}
depends_on = [aws_internet_gateway.gw]
}
resource "aws_nat_gateway" "gw" {
allocation_id = aws_eip.nat.id
subnet_id = aws_subnet.public[0].id
tags = {
Name = "${var.vpc_name}-nat-gateway"
}
depends_on = [aws_internet_gateway.gw]
}
# Route Tables
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
tags = {
Name = "public-route-table"
}
}
resource "aws_route" "public_igw" {
route_table_id = aws_route_table.public.id
destination_cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.gw.id
}
resource "aws_route_table" "private" {
vpc_id = aws_vpc.main.id
tags = {
Name = "private-route-table"
}
}
resource "aws_route" "private_nat" {
route_table_id = aws_route_table.private.id
destination_cidr_block = "0.0.0.0/0"
nat_gateway_id = aws_nat_gateway.gw.id
}
resource "aws_route_table_association" "public" {
count = var.subnet_count
subnet_id = aws_subnet.public[count.index].id
route_table_id = aws_route_table.public.id
}
resource "aws_route_table_association" "private" {
count = var.subnet_count
subnet_id = aws_subnet.private[count.index].id
route_table_id = aws_route_table.private.id
}
以下は ./main.tf のローカル変数から取得します。
./aws/vpc/variables.tf
variable "vpc_name" {
type = string
description = "the name for the vpc"
}
variable "cidr_block" {
type = string
description = "the cidr block to use for the vpc"
}
variable "subnet_count" {
type = number
description = "how many private and private subnets to create"
}
以下は ./main.tf のモジュール呼び出しに返します。
./aws/vpc/outputs.tf
output "vpc_id" {
value = aws_vpc.main.id
description = "the id of the vpc"
}
output "vpc_cidr_block" {
value = aws_vpc.main.cidr_block
description = "the cidr block of the vpc"
}
output "private_route_table_id" {
value = aws_route_table.private.id
description = "the private route table of the vpc"
}
output "public_route_table_id" {
value = aws_route_table.public.id
description = "the public route table of the vpc"
}
以下にはRoute53とSimpleADを設定します。 ./aws/dns/main.tf
data "aws_vpc" "main" {
id = var.vpc_id
}
data "aws_availability_zones" "available" {
state = "available"
}
locals {
dns_subnet_availability_zones = slice(data.aws_availability_zones.available.names, 0, 2)
}
resource "aws_subnet" "dns" {
count = length(local.dns_subnet_availability_zones)
vpc_id = var.vpc_id
cidr_block = cidrsubnet(var.dns_subnet_cidr_prefix, 4, count.index)
availability_zone = local.dns_subnet_availability_zones[count.index]
tags = {
Name = "directory-service-${local.dns_subnet_availability_zones[count.index]}"
}
}
resource "aws_route_table_association" "dns" {
count = length(aws_subnet.dns)
route_table_id = var.private_route_table_id
subnet_id = aws_subnet.dns[count.index].id
}
resource "aws_network_acl" "dns" {
vpc_id = var.vpc_id
subnet_ids = aws_subnet.dns[*].id
tags = {
Name = "directory-service-acl"
}
}
resource "aws_network_acl_rule" "ingress" {
network_acl_id = aws_network_acl.dns.id
egress = false
protocol = -1
rule_number = 100
rule_action = "allow"
cidr_block = data.aws_vpc.main.cidr_block
from_port = 0
to_port = 0
}
resource "aws_network_acl_rule" "egress" {
network_acl_id = aws_network_acl.dns.id
egress = true
protocol = -1
rule_number = 100
rule_action = "allow"
cidr_block = "0.0.0.0/0"
from_port = 0
to_port = 0
}
resource "aws_directory_service_directory" "dns" {
name = var.directory_name
description = "internal directory for dns forwarding over vpns"
type = "SimpleAD"
size = "Small"
password = var.directory_password
vpc_settings {
vpc_id = var.vpc_id
subnet_ids = aws_subnet.dns[*].id
}
}
variable "vpc_id" {
type = string
description = "the id of the aws vpc"
}
variable "private_route_table_id" {
type = string
description = "private route table id of the aws vpc"
}
variable "directory_name" {
type = string
description = "the name for the directory"
}
variable "directory_password" {
type = string
description = "the admin password for the directory"
}
variable "dns_subnet_cidr_prefix" {
type = string
description = "the cidr prefix for aws dns server subnets"
}
output "dns_ip_addresses" {
value = split(",", join(",", aws_directory_service_directory.dns.dns_ip_addresses))
}
output "dns_network_acl_id" {
value = aws_network_acl.dns.id
}
続きの投稿は以下を予定していますが、投稿日は未定です。気長にお願いします。
サーバ業務周りの管理、運用について役に立ちそうなナレッジをまとめました。
長期的に書いているため用語に統一性がなかったり、不足分など随時修正したいと思います。
最近はクラウドにて必要スペックを自由に決めることができるため、最低限必要なスペックは確保したい。 そのため以下は検証、確認しておきたい。
利用したいミドルウェアに依存します。また、Rethatのように有料か無料かも判断材料に入ってきます。 例えば、Ubuntu、CentOSどちらも使える場合は、以下で判断すると良いかもです。
CentOS開発終了が決定されており、最新のCentOS8は 2021年12月31日でサポートが終了します(ただしCentOS7は2024年6月30日までサポート)。 CentOSはCentOS Streamとなり、常に最新パッケージのみしか提供されないくなるため、MW以上の対応を常時やらないといけなくなります。
CentOSを導入される方はそのことを考慮した上で検討する必要があります。
ただ、Linuxディストリビューションはたくさんあるため、この機に色々冒険するのもありかと思います。 また最近はクラウド利用が進んでいるため、提供されているOSを使えば、大きな負担にはならないはずです。
OS同様MWにも注意が必要です
Debianであれば dpkg -l | grep <パッケージ名> 、RHELであれば yum list installed | grep <パッケージ名> で検索して無理のない範囲で最小構成を目指しましょう。
Nginxにする必要が特にない場合はプリインストールされているApacheにしましょう。 初期インストールされているものは推奨されているMWです。
商用でサーバを使う場合最低限以下は確認したい。
ss -auntコマンドや、lsof -iコマンドで必要なポートだけlistenするようにしてください。 不明なポートはiptablesなどで閉じましょう。 つまりインストールされているMWの使用ポートは全て把握する必要があります。
初心者の場合は以下でざっくり設定をします 個人的な環境で設定を行う場合は
より細かいフィルタ制御をしたい方は iptables(CentOS/Ubuntu共通) を使用します
サポート切れや脆弱性のあるパッケージは随時アップデートを行いましょう
使用しているOSでパッケージが古いかどうかは apt-cache などで確認できます
OSSとして ClamAV が比較的有名で検討材料になるかと思います。
個人アカウントは必要最低限の権限のみ付与しましょう。 ホスト全体に影響がでるような変更は sudo をつけるようにします。
ホストが生成されるログはエビデンスにもなるため重要です。
Linux ではストレージ容量がいっぱいになると大半のコマンドが打てなくなり、最悪サーバ上のアプリは停止します。
データベースだけでも膨大に種類があるため、慎重に決める必要がある。 以下の要件で決める。
複雑なテーブル要件と各テーブルのリレーションが必要
-> リレーショナルDB(OracleDB、MySQL、PostgreSQLなど)
key、valueのように単純なテーブル構成(各テーブル同士のリレーショナルもいらない)
-> NoSQL (Cassandra/MongoDB)
※Redisは特殊な用途で使われてるため、対象外。更なる検討が必要。
よく出る話題です。 以下要件で選択しましょう。
PostgreSQLは大規模対応のため、追記型アーキテクチャを採用しており、UPDATEを実行すると DELETE -> INSERTする形になっています。
MySQLような単純変換ではなく、実質2コマンドを実行するため小規模だとパフォーマンスが出ませんが、大規模での大量UPDATEとなるとINSERTの処理に探索が不要なためPostgreSQLの方が有利になります。
個人的にまずはMySQLを使用して、パフォーマンスが出なかったり、機能不足を感じた場合はPostgreSQLに移行するのもありかと思っています。
各ユーザのホームディレクトリには以下ファイルが生成されています。 これはユーザログイン時に毎回実行されるもので必要に応じて環境変数を追加してデフォルト環境変数として扱えるようにします。
~/.bashrc ~/.bash_profile
visudo のsetenvで設定します。 例えばsudo実行時は各ユーザ毎の実行ファイルを使うときになどが当たります。
%hoge ALL=(ALL) SETENV: /usr/bin/fuga
監視系のように更新頻度の多いサーバ設定ファイルは、複数人数で何度も編集することによりファイルの中身が煩雑になったり、
万が一ファイル損失した際、リカバリが難しくなってしまいます。
できればgithubなどで管理し、crontabで定期的に git add -> git commit -> git push して管理しましょう。
特に理由がなければ、以下でrootでの直接ログインを不可にしておきましょう。
PermitRootLogin no
rootで作業したい場合は、ログイン後にsudoを利用してroot権限での作業をしましょう。そうしないと誰がrootで作業したのかログからはわからくなってしまいます。
visudo内での設定順序によっては、sudoがうまく働かない場合があります。(例えば設定したのにNOPASSでsudo実行できないなど) これは visudo内のファイル設定が上から処理されるからです。 例えば以下のように設定してしまうと①のユーザ設定が②で上書きされてしまいます。
Aユーザの設定 --- ① Aユーザを含むグループの設定 --- ②
そのため、①のような小さい単位の設定を行う場合はvisudo内の下部に記載してください。 また、そのようなトラブルを避けるため、include ディレクトリを設けて小さい単位の設定はその中で設定するルールにしておくと良いと思います。
rsyslogのRainerScriptによって設定ファイルにスクリプトを定義することができます。
※注意 単純にif文を使えばRainerScriptを使用しているとみなされるだが、一部のrsyslogのレガシー設定と併用が不可能なため気をつける必要がある。 またRainerScriptはrsyslogの機能の中でも比較的新しい機能であるためなるべく最新のrsyslogをインストールしてください。
rsyslogの機能でratelimitが存在するためそれが一番簡単です。 またこれも RainerScriptで設定が可能なためratelimit以外の複雑なログ処理を必要とする場合はRainerScriptを使いましょう。
ログは増え続けるものなので必ず商用サーバにはログローテションは必要です。 以下のように、一定周期でアーカイブサーバなどにローテーションしておきましょう。
# 以下をcrontabに設定する
find /var/log/ -mtime +365 -exec rm {} +;
使用する実行ファイルは必要に応じてsystemctlで管理しましょう
vi /etc/systemd/system/<service名>.service
[Unit] Description=<Description> #Descriptionを書くことにより、systemctlコマンド実行時にサービス概要を確認できる After=network.target syslog.target # [Service] Type=simple # ExecStartPre=/usr/local/sbin/<prestart時の実行コマンド> ExecReload=/usr/local/sbin/<reload時の実行コマンド> ExecStart=/usr/local/sbin/<start時の実行コマンド> ExecStop=/bin/kill -s TERM $MAINPID [Install] WantedBy=multi-user.target
vi /etc/motd
################## This is a Production !!!! ##################
誤ったshutdownやrebootを防ぐにはいくつかの予防策があります。
shutdownやrebootの実行はroot権限が必要なため、例えばsudoでは実行できないようにすることで、個人アカウントで誤って実行することを防げます。
またmolly-guard を使う方法もあります。
sudo apt install molly-guard
これはsshでログインした時のみ有効ですが以下のようにshutdownしてもすぐにshutdownが実行されず、ホスト名を入力するように促されます。 正しいホスト名を入力すればそのままshutdownが実行されます。
# shutdown -h now W: molly-guard: SSH session detected! Please type in hostname of the machine to shutdown:
有名な例をあげると以下ですが、他にもたくさんあるので、誤って打ちそうなコマンドを探すと良いでしょう。
| 危険コマンド | 説明 |
|---|---|
| sudo rm -rf / | 全てを無にする |
| sudo mkfs.ext4 /dev/sda | /dev/sdaとはOS実行に必要な情報が入る記憶領域なためこれを初期化すると・・・ |
| mv /etc/* /dev/null | ありとあらゆる設定ファイルを無にする |
| dd if=/dev/random of=/dev/sda | /dev/sdaをランダムで上書きしてしまうので・・・ |
これらのコマンドは誤って打たないように同じ形のコマンド実行をaliasで実行不可な状態にしたり、スクリプトで監視したりする方法があります。
構築を行っていく際に同じ工程が何度も発生するのであれば、 コマンドを結合したり、for分使ったりしてどんどんスクリプト化していきましょう。 その方がコマンドの打ち間違えも防げます。
繰り返し実行するコマンド群が発生 ↓ コマンドを改修(コマンドの結合やスクリプト化) ↓ shellscriptを本格的に作成する
セキュリティの重要性が高まる中でsshも多要素が求められてきたようです。 商用でのサーバ管理では多要素認証はsshのみならず全て必須になっていくでしょうから、sshの多要素認証対応はしておきましょう。
インターネット直接繋がっているホストはDDoS攻撃の的にされるので、必ずssh や ftpなどのログイン、転送系のポートは変更しておきましょう。 セキュリティを強固にしておけば不正侵入は防げますが、DDoSによるリクエストをL4で受け取ってしまうとサーバダウンに繋がってしまいます。
サーバ運用の際に使うコマンドについてまとめました
インフラ業務ではsshとても多様するため正直すべてのオプションを把握しておいた方が良いですが、
| コマンドオプション | 説明 |
|---|---|
| ssh -i <秘密鍵のパス> | 鍵認証でアクセスする際に使います |
| ssh -p <ポート番号> | sshポートは22ですが、それ以外でlistenされているホストにログインする際には指定する必要があります |
| ssh -L <転送元ポート番号>:<転送先ホスト名またはIP>:<転送先ポート番号> | ポートフォワードに使います |
| ssh -A | 一般的には秘密鍵の転送を経由する踏み台サーバにすることにより、ローカル環境にある秘密鍵で踏み台先のホストにアクセスできるようにします |
| ssh -o ServerAliveInterval=<keepaliceパケットの送信間隔> | 意外によく使うオプションで、特にパブリッククラウドでのインスタンスでは長期間のセッションを防ぐため一定時間でsshセッションを切断する仕組みが儲けられています このオプションを使うことにより一定間隔でkeepaliveパケットを投げることができるため、予期しない切断を防ぐことができます |
sshコマンドの後ろにコマンドを書くことによってssh先でコマンドを実行できます
ssh <ユーザ名>@<ホスト名> <ssh先で実行したいコマンド>
スクリプト化した際など、パスワードなしでこれを実行したい場合は sshpassコマンドを併用します。
Windowsですと、ターミナルツールとしてteratermが一般ですが、teratermをインストールする際に一緒にインストールできる LogmeTT の使用をお勧めしたいです。
とても使いやすいマクロツールでこれを使えば私が知る限りののログインプロセスは自動化できます。
Macの場合はlinuxと同様に ssh_config を作成するようにします。
また、ターミナルツールには iTerm2 を使用します。
インフラ構築の場合、大抵は踏み台サーバを経由して対象サーバの構築や閲覧を行うかと思います。 踏み台先のサーバに例えば80番ポートでブラウザアクセスしたい場合はポートフォワードを使用します。 また踏み台を2回経由しないといけない場合などでは多段ポートフォワードを実行することによってブラウザアクセス等が可能になります。
ローカルPC ↓ 踏み台サーバ1 ↓ 踏み台サーバ2 ↓ 対象サーバ(8080ポートでアクセスしたい!)
上記のような場合は以下手順でsshコマンドを実行します
# ローカルサーバで実行 ssh -L 2222:<localhost>:22 <ユーザ名>@<踏み台サーバ1> # 踏み台サーバ1で実行 ssh -L 2223:<localhost>:22 <ユーザ名>@<踏み台サーバ2> # 踏み台サーバ2で実行 ssh -L 8081:<localhost>:8080 <ユーザ名>@<対象サーバ> ブラウザ localhost:8081 にアクセス
踏み台先から鍵認証対象サーバにアクセスしたい場合は秘密鍵を踏み台に置かずに鍵転送を使用しよう。 秘密鍵は絶対に複製せず、ローカルにのみ置いて管理してください。
# ssh エージェントを有効化 $ eval `ssh-agent` # 転送したい秘密鍵を sshエージェントに登録する $ ssh-add ~/.ssh/id_rsa # 鍵転送を実行してログイン $ ssh -A <ログインユーザ>@<秘密鍵を使用したいホスト> # 秘密鍵を使いたいホストにてsshエージェントが有効であることを確認(Agent名が) $ ssh-add -l Agent pid 37343
Ansibleで一般的になったような気がしますが、公開鍵の転送には ssh-copy-id を使用します。
比較的有名なテキストエディタは以下でvimだけ使えれば良いと思います。
vimにも種類がありまして、vim.tinyが最小構成のもので機能が限られます。
最初は使いやすいですが、すぐに編集スピードに限界を感じるかと思います。
bashではなくzshでプリインストールされているvimは比較高機能なものであり、これに慣れておくことをお勧めします。
実践Vim 思考のスピードで編集しよう! (アスキー書籍) | Drew Neil, 新丈 径 | 工学 | Kindleストア | Amazon
linux でvisudoなどを利用する際にテキストエディタがnanoになっている時があるのですが、vimに変えたい場合は以下で変更できます。
sudo update-alternatives --set editor /usr/bin/vim.basic
一時的にvimにしたい場合は以下のようにコマンド前に環境変数を入れて変更する
EDITOR=vim visudo
teratermのプロンプトが見えていない時や、termの表示が荒れてしまったときに、
よく ctrl+c や ctrl+z したり、 enter 連打したりと散見されますが、
想定外のコマンドが実行されてしまったり、ジョブを誤って停止してしまったりとトラブルに繋がってしまう可能性があるため、
ctrl+l で対処するようにしましょう。
ctrl+lでプロンプトに何もないこと確認した上で Enterを連打してログの見やすさを意識すると良いかと思います。
ctrl+a,e をはじめ、bash、zsh上では様々なショートカットが使えるため、覚えるようにしましょう。
古いLinux OSの場合は参照先のパッケージサーバがサポートを終了している場合があります。
その場合は /etc/apt/source.list にてパッケージサーバを変更する必要があります。
大抵はアーカイブとして見つかりますが、見つからない場合は早期にOSのバージョンアップが必要になります
pathは一歩間違えると事故につながりますので、短く書くように工夫しましょう。
cp /var/log/source_log /var/log/copy_log ❌
cp /var/log/{source_log, copy_log} ⭕️
技術の発展とともに秘密鍵の安全性も毎年変わってきます。 秘密鍵は一定の安全性を確保する必要があるため、使用時期に応じてNISTが定めている暗号とハッシュを使う必要があります。
https://www.ipa.go.jp/files/000013413.pdf
sshでログインすると ~/.ssh/known_hosts というファイルがssh実行元に作成されますが、これをログインする前に作成しておきたい場合はssh-keyscanコマンドを使用します。
初回のログインでこの ~/.ssh/known_hosts を作るか選択する必要があるのですが、これがスクリプト作成や自動化などでの妨げになります。
ssh-keyscanコマンド を使った後にsshログインすれば聞かれなくなります。
コマンドモードで 1GdG と入力。間違えたらuでUNDOしましょう。
ついInsertモードで移動しがちだが、vimは極力カーソル移動を減らすように設計されているのでコマンドモードを駆使して移動しよう。
行移動なら 1G 3G G など
ファイル内で置き換えを行う際にはコマンドモードにて :%s/<置換前>/<置換後>/gc としましょう。
cをつけることによって置換を一つずつ確認することができます。
sudo vimでファイルを編集してしまうと所有者がrootでないファイルも所有者rootにされてしまいます。
大きなトラブルの元につながりますので、特に理由がない場合は代わりにsudoeditを使うと良いでしょう。
journalctl
例えば転送に何時間もかかるようなファイルの移動はscpではなくrsyncを使って転送するようにしましょう。
shutdownコマンドやrebootコマンドや影響範囲の広い変更コマンドは一度打った後にhistoryから削除しましょう
vi ~/.bash_history
$?は終了ステータスです。直前のコマンドやスクリプトが正常に終了したかどうかを確認することができます。
特にスクリプト作成で使うことが多く、終了ステータスが 0以外(異常終了)の場合は例外処理に流したり、エラーメッセージに分岐させたりします。
<スクリプト or コマンド実行> # 標準出力が0なら直前の正常終了、異常終了 echo $?
$! は直近で実行したプロセスIDを返します。
これもスクリプトで使われることが多く直前に実行したコマンドのプロセスIDを使って別処理に使ったりします。
スクリプトなどでエラーが発生しても標準出力させたくない場合は以下のようにエラーを /dev/null に葬ってしまいます。
<コマンド実行> 2>/dev/null
商用環境で作業を行う際には複数のメンバが同じ画面を見ることになると思います。 直接サブディスプレイで画面を共有しても良いですが、tmuxやscreenを使ってセッションを共有すると良いと思います。
また、sshでリモートログインしている中でコマンド実行中に作業者PCの異常で通信不可になってもセッションは残るため、商用環境での作業では必ずtmuxまたはscreenのいずれかを利用しましょう。
スクリプトでも応用が効き、複数セッションを同時に立ち上げて各セッションでスクリプトを実行することも可能です。
同じホストの他ユーザの実行画面を閲覧できます。商用環境で作業をする際に便利です。 tmuxとは違いセッションを共有するのではなくttyに標準出力された内容を他ユーザにも標準出力される仕組みのようです。 そのためtmuxやscreenと違いセッションを奪うようなことはできません。
データセンタ作業では、日頃では中々触らないサーバ作業が存在します。 またデータセンター作業に必要な準備については以下に記載しています。
メーカ別の主なサーバ製品は以下になります。 メーカによって仕様が全く違うため、使用する際にはメーカー、製品毎の検証は必要です。
| サーバ名 | 感想 |
|---|---|
| HPE ProLiant | 数あるサーバの中で一番使いやすいサーバでした。IPMIの管理ユーティリティがしっかりとしていて、故障率も低かった印象です。 |
| Fujitsu PRIMERGY | 故障率がまあまあ高かったですが、ユーティリティ周りがしっかりとしていたため、使いやすい印象です。 |
| DELL Power Edge | ネットワーク周りに難ありでした。想定と違う動き(linkup/down)をする印象でHPEと違い、扱いづらかった印象です。 |
| Supermicro | 確か割安のサーバでしたが、故障率が高く、IPMIユーティリティにもいくつか難ありの印象です。 |
サーバは一般的にとてもでかく重いですが、以下のような小さなサーバも存在します。 これはクラウド需要を見越して、限られたスペースに必要なだけのサーバをできる限り効率的に収納するためのプロジェクトのようです
Open Compute Project Japan | オープンコンピュートプロジェクトジャパンは、OCP (Open Compute Project) の日本コミュニティです。
一般コンシューマー向けPCではほとんど見かけませんが、業務系サーバでは IPMI *1と呼ばれる特殊なインターフェースモジュールが存在します。 業務系サーバではこれがとても大事で主に遠隔からのサーバ管理に使われます。
主にやれることは以下になります
最近ではこのIPMIのREST APIを使用して、BIOSの設定、ファームウェアのVer調整などを構築自動化する動きもあるようです。
IPMIは業務系サーバでは必須のインターフェースモジュールです。 例えばデータセンタ現地での作業を行った後に、サーバのOS再インストールや再起動、OS、フォームウェアのアップグレードなどが必要になった場合、 遠隔でこれらを行おうとすると、少なくともOSが起動してIPがアサインされるまではネットワーク疎通性がなくなってしまい管理ができなくなってしまいます。
これは場合によっては再度IPアサインをデータセンタ現地で行わないといけないため、業務上では大きな遅延に繋がってしまいます。 そのためIPMIでのIP設定はある意味、業務上での命綱となります。
そういった理由もあり、IPMIは物理的に独立したモジュールをサーバ本体に繋ぐような形で実現しており、OSの影響を受けないように設計されています。

BIOSには大きく分けてUEFIとLegacyの2種類が存在しており、日頃見かける上記のようなBIOS画面はUEFIの画面になります。 UEFIは選択式のBIOSで、初心者でも簡単に操作が可能です。
対してLegacy BIOSは CLIのBIOSで、専用コマンドを入力して操作を行います。 UEFIでは対応していない機能が存在していた場合、Legacy BIOSに切り替えて設定を行います。
意外と言葉は出てくるので、概要だけ知っておくと良いと思います。
SFPは光インターフェースモジュールのことで、高速な通信を必要とする場合に使用されます。
ひと昔まではCiscoやJuniperなどのネットワーク機器に使われるのが一般的でしたが、最近ではサーバにも使われるようになっているようです。
また、一般コンシューマ向けのPCでも10GbE以上を搭載したい場合はこれを使う場合があります。 サーバだけでなくストレージでも使うので、データセンタ業務で必ず目にすると思います。


*1:Intelligent Platform Management Interface
SRv6について2021年までに取集した情報を整理して入門書を作りました。 とりあえずSRv6に触れたい方向けの内容になっています。
SRv6とは「Segment Routing over IPv6」の略でセグメントルーティングとIPv6を合わしたNW技術になります。 2017年あたりから多くの https://www.janog.gr.jp/meeting/janog43/program/srv6 SRv6を理解するには主に「セグメントルーティング」と「IPv6」を理解する必要があります。
セグメントルーティングとはソース情報(送信元)をベースとして、トラフィックを細かく管理(トラフィックエンジニアリング)することができるネットワークプロトコルです。
ざっくりとしたイメージは以下となります。

セグメントルーティングでは、ソースから様々なトラフィック制御(ルーティング、QoSなど)が可能になるため、アプリケーションなどと連携するSDNがとても容易になります。
IPv6は128ビット長のパケットで 340×1兆×1兆×1兆 のIP割り当てが可能です。(IPv4は43億ほど) 事実上世界中で一意に使われても枯渇することがないとされています。
既に大規模DCやインターネット回線など広く使われており、最近では一般コンシューマ向けのIPv6に対応したモデムやルータなどもよく見かけるようになりました。
http://www.worldipv6launch.org/measurements/
既に多くのITインフラで利用がはじまってます。
など IPv6には「拡張ヘッダー」と呼ばれる自由に機能を詰め込めるスペースがあり、これを使用することにより SRv6 が実現します。 そのため、プラットフォームがIPv6に対応していればSRv6を利用することができ、導入し易いようです。
新しい技術でまだまだ発展途上だが、すでに採用済み、検討中の企業は多数。
詳細については以下
SRv6の主な仕組み
 https://www.rfc-editor.org/rfc/rfc8754.html
https://www.rfc-editor.org/rfc/rfc8754.html
p23~p27参照
SRv6対応ルータでは様々なコントロールが可能です。
https://tools.ietf.org/html/draft-ietf-spring-srv6-network-programming-28#page-10
| function | 説明 |
|---|---|
| End | Endpoint function The SRv6 instantiation of a Prefix SID [RFC8402] |
| End.X | Endpoint with Layer-3 cross-connect The SRv6 instantiation of an Adj SID [RFC8402] |
| End.T | Endpoint with specific IPv6 table lookup |
| End.DX6 | Endpoint with decapsulation and IPv6 cross-connect Te.g. IPv6-L3VPN (equivalent to per-CE VPN label) |
| End.DX4 | Endpoint with decaps and IPv4 cross-connect Te.g. IPv4-L3VPN (equivalent to per-CE VPN label) |
| End.DT6 | Endpoint with decapsulation and IPv6 table lookup Te.g. IPv6-L3VPN (equivalent to per-VRF VPN label) |
| End.DT4 | Endpoint with decapsulation and IPv4 table lookup Te.g. IPv4-L3VPN (equivalent to per-VRF VPN label) |
| End.DT46 | Endpoint with decapsulation and IP table lookup Te.g. IP-L3VPN (equivalent to per-VRF VPN label) |
| End.DX2 | Endpoint with decapsulation and L2 cross-connect Te.g. L2VPN use-case |
| End.DX2V | Endpoint with decaps and VLAN L2 table lookup Te.g. EVPN Flexible cross-connect use-case |
| End.DT2U | Endpoint with decaps and unicast MAC L2 table lookup Te.g. EVPN Bridging unicast use-case |
| End.DT2M | Endpoint with decapsulation and L2 table flooding Te.g. EVPN Bridging BUM use-case with ESI filtering |
| End.B6.Encaps | Endpoint bound to an SRv6 policy with encapsulation TSRv6 instantiation of a Binding SID |
| End.B6.Encaps.Red | End.B6.Encaps with reduced SRH TSRv6 instantiation of a Binding SID |
| End.BM | Endpoint bound to an SR-MPLS Policy TSRv6 instantiation of an SR-MPLS Binding SID |
SRv6は宛先(終端)にアクセスするのに、宛先までのセグメントIDと各セグメントID間のIPv6ルーティングによって宛先に到達することができます。 あらかじめトポロジ全体のセグメントIDがわかっていれば良いですが、手動で全パターンを終端に設定していくのは大変です。 通常のIPルーティングと同じでSRv6にもコントロールプレーンがいくつか使えます。
<手動でやる場合の絵を書く>
<自動でやることのメリットを絵にする>
セグメントIDをグループ化することによって、各グループに応じたルーティングが可能になります。グループ化すると広報するセグメントIDはグループ内でのやりとりになります。 またこのようなに理論的にネットワーク分割することをネットワークスライシングと呼びます。

https://5g-innovation.com/report/networkslicing-2019-event-report2/
障害発生時の高速経路切替(ここではlocal repairを想定)のことで、SRではTI-LFA(Topology Independent – Loop Free Alternate)という機能でこれを実現しています。
ping や traceroute といったトラブルシュートなどに役立てるためのSRv6機能のこと。
現在 SRv6 は主に以下の方法でハンズオンが可能
iproute2 はLinuxで使えるネットワークユーティリティです。 実は日頃使っているipコマンドのことで、既にSRv6を設定するために必要な機能が備わっています。
root@linux:~# ip -6 route help
Usage: ip route { list | flush } SELECTOR
ip route save SELECTOR
(~ snip ~)
ENCAPTYPE := [ mpls | ip | ip6 | seg6 | seg6local ]
ENCAPHDR := [ MPLSLABEL | SEG6HDR ]
SEG6HDR := [ mode SEGMODE ] segs ADDR1,ADDRi,ADDRn [hmac HMACKEYID] [cleanup]
SEGMODE := [ encap | inline ]
ROUTE_GET_FLAGS := [ fibmatch ]
設定には以下のように全てまたは特定のethのカーネル設定が必要になります。
sysctl net.ipv6.conf.all.forwarding=1 sysctl net.ipv6.conf.all.seg6_enabled=1 sysctl net.ipv6.conf.default.seg6_enabled=1 sysctl net.ipv6.conf.eth1.seg6_enabled=1 # 以下コマンドで事後確認 sysctl -a | grep seg6
echo 100 localsid1 >> /etc/iproute2/rt_tables echo 200 localsid2 >> /etc/iproute2/rt_tables echo 300 localsid3 >> /etc/iproute2/rt_tables echo 400 localsid4 >> /etc/iproute2/rt_tables
以下設定で encap、transit、decap それぞれが可能
ip -6 route add 2001:db10::/64 encap seg6 mode encap segs 2001:db2::2,2001:db5::2,2001:db8::2 dev eth1 table localsid1
ip -6 route add 2001:db2::2/128 encap seg6local action End dev eth1
ip -6 route add 2001:db2::1/128 encap seg6local action End.DX6 nh6 2001:db1::1 dev eth1 table localsid1
またコマンド変数の意味は以下になります また、Namespaceと組み合わせて使用することも可能です Namespaceと組み合わせれば一台のホスト上で仮想的に複数台のノードの定義と紐付けが可能になります

以下githubハンズオンツール(構築/デモ手順はリポジトリ内にあります) https://github.com/vn-cdr/srv6-netns-demo
git clone <git repository> cd srv6-netns-demo vagrant up vagrant ssh sudo su - bash scripts/01_create-namespaces.sh bash scripts/02_create-quagga.sh bash scripts/03_create-ospf6.sh bash scripts/04_create_srv6.sh
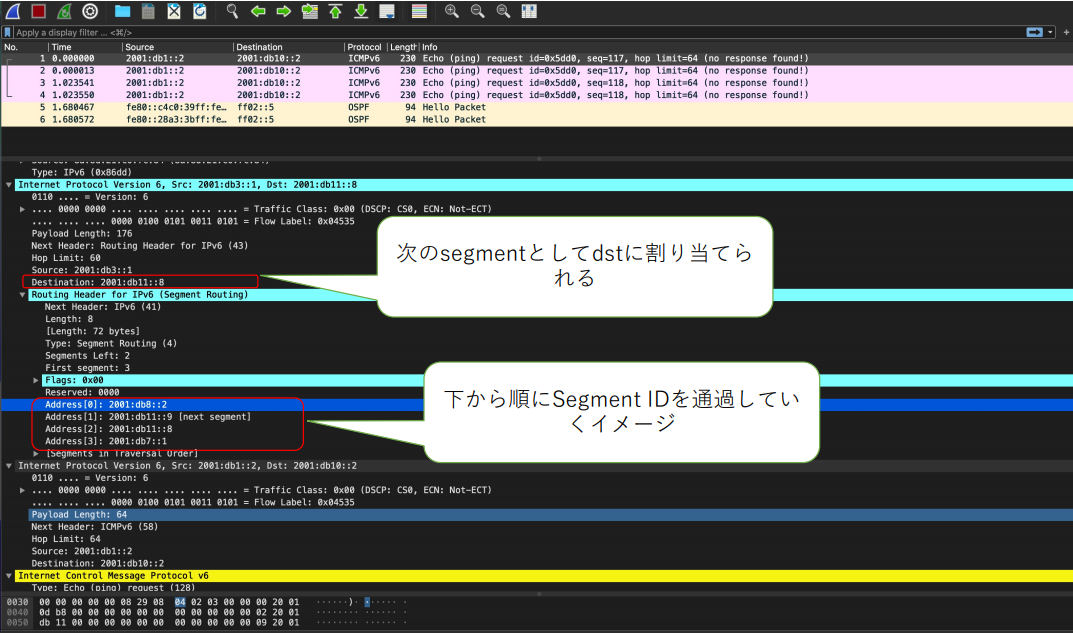
パケットキャプチャで取得した際に下記の通りSRv6 Headerが確認できます
FD.ioプロジェクトで管理されているOSS仮想ルータ。 様々な機能を有している仮想ルータですが、RAMを大きく使用するため、個人にて検証する際には注意。 https://docs.fd.io/vpp/17.07/srv6_doc.html
CMLはCiscoの様々なルータを自由に構成して検証できる、サンドボックスツールです。 CMLを使えば Nexus-9000v や XRv-9000、ASAv など個人では大きな壁であった、NW-OS使用までの環境を瞬時に用意できます。 https://developer.cisco.com/docs/modeling-labs/#!faq/faq---cisco-modeling-labs-v2x
XRv9000 では利用できるバージョンが既にSRv6に対応しており、個人でSRv6環境を構築できます。
RP/0/RP0/CPU0:xrkv-0#show segment-routing srv6 manager
Fri Apr 30 01:23:03.725 UTC
Parameters:
SRv6 Enabled: Yes
Encapsulation:
Source Address:
Configured: 2001:db2::1
Default: 2001:db22::2
Hop-Limit: 255
Traffic-class: Default
Config Op Mode: SRv6
SID Base Blocks:
2001:db2:2200::/40
Summary:
Number of Locators: 1 (1 operational)
Number of SIDs: 2 (0 stale)
Max SIDs: 8000
OOR:
Thresholds: Green 400, Warning 240
Status: Resource Available (0 cleared, 0 warnings, 0 full)
Platform Capabilities:
SRv6: Yes
TILFA: Yes
Microloop-Avoidance: Yes
End Functions:
End (PSP)
End.X (PSP)
End.DX4
End.DT4
End.OP
uN (PSP/USD)
uA (PSP/USD)
uDT6
uDT4
Transit Functions:
T
T.Insert.Red
T.Encaps.Red
Security rules:
SEC-1
SEC-2
SEC-3
Counters:
CNT-1
CNT-3
Signaled parameters:
Max-SL : 3
Max-End-Pop-SRH : 3
Max-T-Insert : 3 sids
Max-T-Encap : 4 sids
Max-End-D : 4
Configurable parameters (under srv6):
Encapsulation:
Source Address: Yes
Hop-Limit : value=Yes, propagate=No
Traffic-class : value=Yes, propagate=Yes
Max SIDs: 8000
SID Holdtime: 30 mins
RP/0/RP0/CPU0:xrkv-0#show segment-routing srv6 ?
locator Locator information
manager SID Manager information
sid SID information across all locators(cisco-support)
trace Show trace data for SID Manager
RP/0/RP0/CPU0:xrkv-0#
XRv9000を使用したSRv6-EVPNは近日中に検証したいと思います。
以上
